Introduction to PyTorch DDP#
DistributedDataParallel (DDP) is a standard approach for training a model
across multiple GPUs, and optionally across multiple nodes. Instead of a single
Python process controlling all GPUs, DDP launches one process per GPU. Each
process maintains its own copy of the model, operates on a different shard of
the data, and synchronizes gradients with other processes at every training step.
The image below illustrates the high-level workflow of DDP:
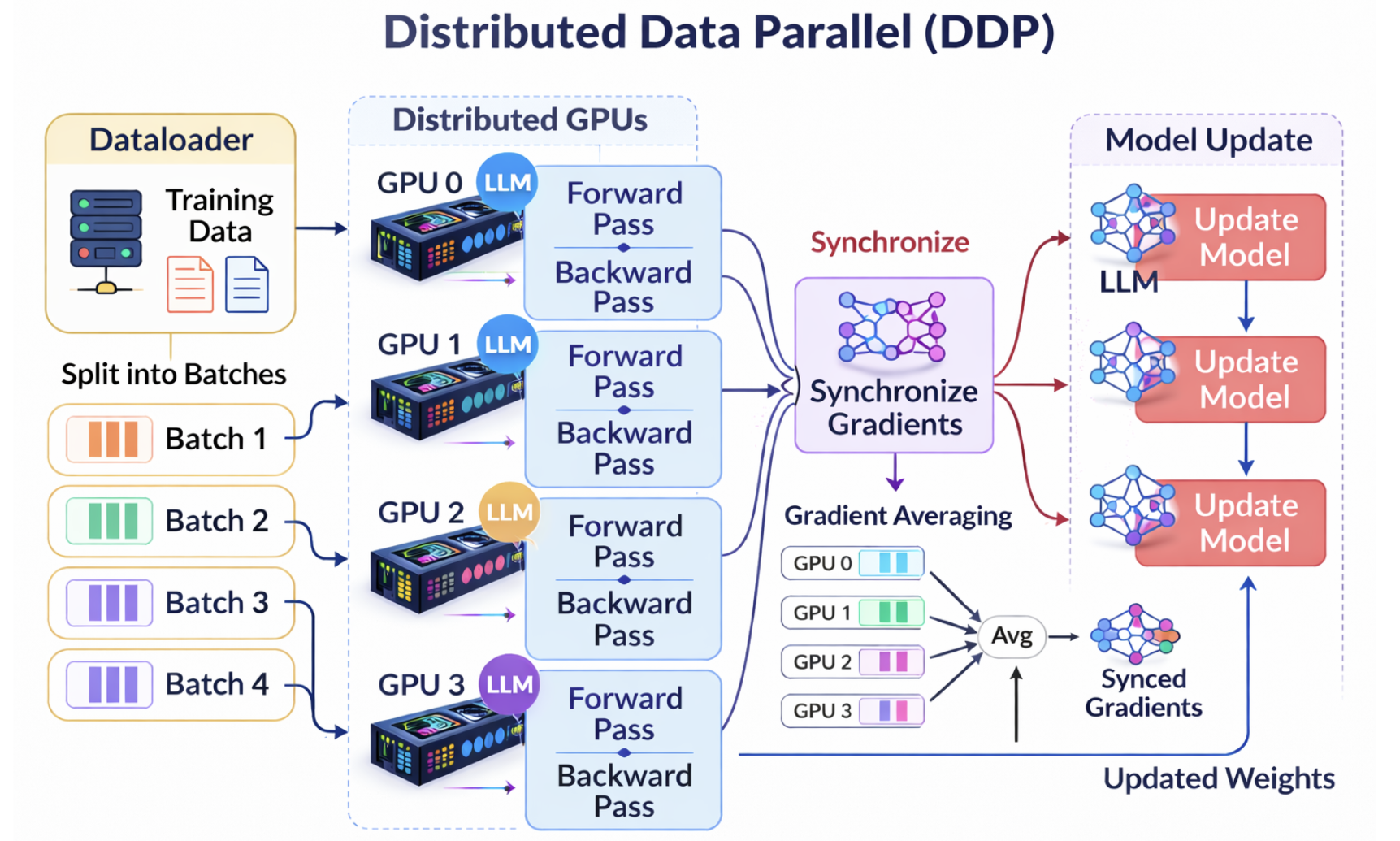
Advantages of DDP#
Faster training: Workloads are distributed across multiple GPUs.
Scalable: Designed for both single-node and multi-node training.
Efficient execution model: The one-process-per-GPU design avoids many bottlenecks present in older data-parallel approaches.
When to use DDP#
Use DDP when at least one of the following applies:
You want to utilize more than one GPU.
Training on a single GPU is too slow.
Your dataset is large enough to benefit from parallel data processing.
If you are experimenting with a small model, start with single-GPU training first, then move to DDP once the baseline is stable.
Show me the code!#
Note
This section uses the DDP example from the companion examples repository.
You can download it from
GitHub
into your home (~) directory and run:
cd amii-doc-examples
uv sync # create virtual environment and install dependencies
cd src/distributed_training
At a high level, a DDP training script includes the following steps:
Initialize the distributed process group.
Bind each process to one GPU (
local_rank).Wrap the model with
DistributedDataParallel.Use
DistributedSamplerso each process receives unique data.Save checkpoints and log metrics from rank 0 only.
Open cancer-classification-ddp.py and follow along.
In the if __name__ == "__main__": block, we retrieve the rank,
local rank, and world size from environment variables set by
torchrun.
rank: global identifier of the process
local rank: index of the process on the current node
world size: total number of processes across all nodes
These values are required to correctly configure distributed training.
Next, we initialize the process group using setup_comm(), which internally
calls torch.distributed.init_process_group(). This sets up communication
between processes using a backend such as NCCL (the recommended backend for GPUs).
We then bind each process to a GPU:
device = torch.device(f"cuda:{local_rank}")
torch.cuda.set_device(device)
This ensures that each process uses the correct GPU. We also verify that the number of available GPUs is sufficient for the launched processes.
The next key component is DistributedSampler. Since each process runs
independently, it must operate on a distinct subset of the dataset.
DistributedSampler partitions the dataset into non-overlapping shards based
on rank and world_size.
When constructing the DataLoader, we pass the sampler:
train_loader = DataLoader(train_data, batch_size=batch_size, sampler=distributed_sampler, drop_last=True)
This ensures that all processes collectively cover the dataset without overlap.
Note that DistributedSampler does not require inter-process communication.
Each process deterministically computes the same global ordering of indices and
selects its own slice.
Next, we create the model and move it to the GPU. When resuming from a checkpoint, we must account for whether the model is wrapped with DDP:
state_dict = torch.load(checkpoint_id, map_location=device)
model_to_load = model.module if isinstance(model, DDP) else model
model_to_load.load_state_dict(state_dict["model_state_dict"])
optimizer.load_state_dict(state_dict["optimizer_state_dict"])
Accessing model.module retrieves the underlying model, which is required when
loading checkpoints.
We then wrap the model with DDP:
model = DDP(model, device_ids=[local_rank])
This enables distributed training. During loss.backward(), DDP automatically
performs gradient synchronization (via all-reduce) across all processes so that
each replica updates its parameters identically. At construction time, DDP also
broadcasts model parameters from rank 0 to all other ranks to ensure consistent
initialization.
When saving checkpoints and logging metrics, we typically restrict these operations to a single process (usually rank 0) to avoid duplication:
if rank == 0 and ((epoch + 1) % SAVE_EVERY_N_EPOCHS == 0 or epoch == NUM_EPOCHS - 1):
ckpt_id = os.path.join(CHECKPOINT_DIR, "latest")
save_checkpoint(model, optimizer, epoch, ckpt_id)
At the end of training, we clean up:
dist.destroy_process_group()
This releases resources and finalizes collective communication.
First run on Slurm#
Now that we understand the code, let’s run it on a cluster using Slurm.
Consider the job script launch_cancer_classification.sh. It supports both
DDP and FSDP, but here we focus on DDP.
The script requests 2 nodes with 1 GPU each (2 GPUs total) and a wall time of 1 hour.
The target parameter specifies the training mode (ddp or fsdp).
Here, we set it to ddp.
Next, we determine the IP address of the first allocated node and use it as the rendezvous endpoint. This allows all processes to discover each other before training begins.
During rendezvous, each process is assigned a unique global rank in the range
[0, world_size - 1].
We also set a fixed port (29500), which is commonly used for PyTorch
distributed training.
Inside the srun block, we detect the number of GPUs per node and set
--nproc-per-node accordingly. This ensures one process per GPU, which is
required for DDP.
Although DDP can run on CPUs, this configuration is uncommon and not testd by us.
We then launch the job with torchrun. Key arguments include:
--nnodes— number of nodes--nproc-per-node— processes (GPUs) per node--rdzv-backend— rendezvous backend--rdzv-endpoint— rendezvous address and port--rdzv-id— unique job identifier
Submit the job:
sbatch launch_cancer_classification.sh ddp
Run this command in the src/distributed_training directory.
Monitor the job:
squeue -u $USER
View logs:
tail -f cancer-classification-ddp_0.txt
Understanding the batch count#
The dataset contains 455 samples, and the batch size is 8 per GPU.
Each GPU processes 28 batches per epoch, so:
28 batches × 2 GPUs = 56 batches total
This happens because DistributedSampler splits the dataset evenly across
processes.
Therefore:
56 batches × 8 samples = 448 samples per epoch
The remaining 7 samples are dropped because they do not form a full batch.
This occurs when drop_last=True is set in the DataLoader.
Summary#
DDP is the recommended starting point for distributed training in PyTorch. It is simple, efficient, and scales well across GPUs and nodes.
In the next section, we introduce Fully Sharded Data Parallel (FSDP), which reduces memory usage and enables training significantly larger models.